Workshop Statistics: Discovery with Data, Second
Edition
Topic 21: Tests of Significance I: Proportions
Activity 21-1: Cola Discrimination (cont.)
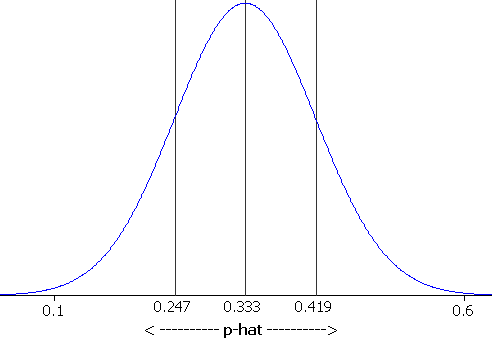
(a) .333
(b) This value is a parameter since it's describing the underlying
true probability, q
(c) The sample distribution is approximately normal with mean .333,
and standard deviation .086.
(d) Yes, the sample size is large enough so that nq>
10 and n(1 - q) > 10.
(e)
probability: .0001 (z=3.88)
(f) Based on this probability, we would consider such a sample
result
very surprising if someone is just guessing. We would not consider it
so
surprising if we believed that the subject is not just guessing, but
really
does have some ability to discriminate among the sodas.
(g) Let q = true probability of correctly
identifying the second brand
(h) Ho: q = .333 (they are just
guessing)
(i) .333
(j) Ha: q > .333 (their
actually
probability is higher than .333)
(k) No, sampling variability.
(l) A: .333; B: .400; C: .500
(m) These proportions are statistics because they describe samples,
not the population.
(n) yes
(o) .086
(p)
(q) .78
(r) .2177
(s) It is not very unlikely.
(t) test statistic: 1.94; p-value: .0262
(u) Yes, based on this p-value, we would reject the null hypothesis
at the .05 significance level that Celia is just guessing because .0262
(the p-value) is less than .05.
(v) No, because the p-value is not less than .01.
(w) No, because her proportion is .333, which is equal to the
hypothesized
value. Since her sample proportion already wasn't better than what we'd
expect if she's guessing, it will not provide evidence against
that
hypothesis.
(x) Neither Alicia nor Brenda showed sufficient evidence to convince
us they were doing better than guessing. Celia, however, had a sample
result
that would happen in about 2% of samples if someone was just guessing.
This is moderate evidence against the null hypothesis that she is just
guessing. Instead we might be willing to conclude she has the ability
to
discriminate among the three sodas.
(y) 30 * .333 > 10 (actually, it equals 9.99, but this is
only
because we cannot use a decimal form of 1/3 without truncating the
number
of digits)
30 * (1 - .333) >
10
Activity 21-2: Baseball "Big Bang"
(a) Ho: q = .75 (A big
bang
occurs in 75% of Major League Baseball games)
(b) Ha: q < .75( A big bang
occurs in less than 75% of Major League Baseball games)
(c)
<-----------------  ------------------->
------------------->
(d) .515
(e) Yes, this sample proportion is less that .75 and therefore
consistent
with Marilyn's (alternative) hypothesis.
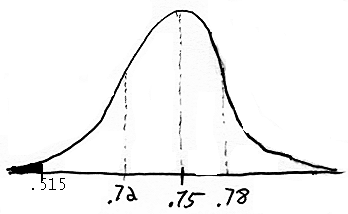
(f) z = -7.48; p-value < .0003
(g) Based on this p-value, the sample data provide very strong evidence
to support Marilyn's contention that the proportion cited by the
grandfather
is too high to be the actual value because the p-value is much
less
than .001.
(h) Ho: q = .5 (Marilyn's claim)
Ha: q¹ .5 (Marilyn's claim
is wrong)
(i) z = .44; p-value = .663
(j) Based on this p-value, the sample data provides no evidence to
reject Marilyn's claim, since .663 > .1. We would fail to reject H0,
the sample data does not give us evidence to disprove Marilyn's
conjecture.
We'd get a sample result like this in about 66% of samples if q
= .5. Doesn't seem very unusual.
Activity 21-3: Flat Tires
(a) The variable of interest in this activity is which tire people will
pick at random, categorical.
(b) The parameter of interest q= the
proportion
of American drivers (or of students at your school) who pick the right
front tire.
(c) .25
(d) Ho: q = .25 (people are
equally
likely to pick the right front tire)
(e) Ha: q > .25 (people
choose
the right front tire more often than they would if they were picking at
random)
(f)-(g) Answers will vary from class to class.
[Check nqo and n(1-qo)]
Activity 21-4: Flat Tires (cont.)
(a) We would need to know the sample size in order to answer this
question.
(b)-(c)
|
sample size
|
"right front"
|
p-hat
|
z statistic
|
p-value
|
alpha = .10?
|
alpha = .05?
|
alpha = .01?
|
alpha = .001?
|
|
50
|
15
|
.30
|
0.82
|
.207
|
no
|
no
|
no
|
no
|
|
100
|
30
|
.30
|
1.15
|
.124
|
no
|
no
|
no
|
no
|
|
150
|
45
|
.30
|
1.41
|
.079
|
yes
|
no
|
no
|
no
|
|
250
|
75
|
.30
|
1.83
|
.034
|
yes
|
yes
|
no
|
no
|
|
500
|
150
|
.30
|
2.58
|
.005
|
yes
|
yes
|
yes
|
no
|
|
1000
|
300
|
.30
|
3.65
|
.000
|
yes
|
yes
|
yes
|
yes
|
(d) Sample size plays a key role in determining whether a sample result
of 30% is significantly greater than a hypothesized value of 25%.
With a large sample size, as we see when n = 1000, a sample
result
of 30% is significantly greater than the hypothesized
value.
Eventually, for a big enough sample size, any result will be
significantly
greater than the hypothesized value!